LegendWechatBot 项目进程 Week2(2025-03-10 ~ 2025-03-16)

LegendWechatBot 项目进程 Week2(2025-03-10 ~ 2025-03-16)
Kanwuqing在下文中, LWB代表 LegendWechatBot, LBW同理
命令处理规范
在LBW的前身作品中, 我曾经尝试过使用NLP技术来处理用户的指令, 效果却不尽人意. 原因是NLP在处理中文指令时, 效果并不理想, 同时还会遇到各种意想不到的语法或者逻辑问题. 因此, 在LBW中, 我决定采用一种更为简单直接的方法来处理用户的指令, 即使用命令处理规范.
指令格式
在LBW插件中, 有两种指令格式, 分别是简略版和详细版. 其中简略版是每个插件都需要具备的, 而详细版则是供要求参数较复杂, 对于返回结果要求更高, 更精细化的用户使用
简略版
该格式受到Python函数调用格式启发
简略版指令格式如下: 1
插件别名 指令参数1 指令参数2 ... 指令参数n
调用简略版指令需要私聊或@
例如: 1
@bot 天气 查询 上海 今天
详细版
详细版指令受命令行命令格式启发
详细版指令格式如下: 1
/指令 -参数1 参数值1 ... -参数n 参数值n
1
/weather -m pre -c 上海 --date 2025-03-10
指令处理
简略版指令很好处理, 不断地startswith然后split即可
详细版指令由于不知道每个插件所需的参数, 因此需要使用正则表达式来预解析指令, 代码如下
1 | import re |
项目新增结构
1 | LegendWechatBot |
插件规范
在LBW中, 我建议每个插件都需要遵循一定的规范, 以便更好地管理和维护. LBW的插件规范主要包括以下几个方面:
插件目录结构
每个插件都需要有一个独立的目录, 目录名即为插件名. 插件目录下需要包含以下文件:
config.yaml: 插件配置文件, 用于存储插件的配置信息.__init__.py: 占位main.py: 插件的主程序文件, 包含插件的入口函数和指令处理函数.
配置文件
配置文件用于存储插件的配置信息, 最外层为插件名, 其中比需包含 enable 字段用来管理该插件是否启用; 包含 description 以及 author 用来显示插件简介和作者; 包含 cmd 用来规定简略指令. 以下是为示例
1 | TCM: |
主程序文件
主程序文件是插件的入口函数和指令处理函数, 需要包含和插件名同名的类, 该类需继承自 plugin.py 中的 PluginBase 插件基类, 处理消息的函数需使用 on_message 装饰器并使用async关键字进行异步处理, 同时需要对简略指令进行SJ(特判), 以输出插件的详细指令用法, 以下为示例
1 | # plugins/Demo/main.py |
新增功能
数据库管理
有数据才有服务
在LegendWechatBot中, 核心维护增添的数据库共有两个: LegendBotDB 与 messageDB.
LegendBotDB
LegendBotDB是用于存储个性化用户和群聊信息的数据库 (插件相关的不存, 留给插件自己存)
LegendBotDB不会在每次启动时清空, 但提供了清空的方法 recreate (用于更新字段时)
Users 表主要需要维护的字段有: - id:
用户或群聊的唯一标识符 - points: 用户积分 -
running: 用户或是否在运行大任务 - black:
用户是否在黑名单
Groups 表主要需要维护的字段有: - whitelist:
需要处理消息的群聊白名单
messageDB
messageDB是用于存储需要处理消息的数据库, 主要用于存储消息的发送者, 接收者, 消息内容, 消息时间, 消息类型, 消息状态等信息, 便于回溯
messageDB会在每次启动时清空
Messages 表主要需要维护的字段有: - id:
消息的唯一标识符 - from_id: 消息的发送者 -
to_id: 消息的接收者 - content: 消息的内容 -
timestamp: 消息的时间 - type: 消息的类型
自动添加好友
通过使用 bs4 解析好友验证消息(类型为37)content字段后可以得到
v3和v4字段,
通过这两个字段可以调用微信接口从而实现自动添加好友
1 | # plugins/AcceptFriend/main.py |
在添加新好友后, 系统会发送一条消息(类型为10000), 消息内容为
你已添加了XXX,现在可以开始聊天了, 此时需要通过 bs4
解析消息内容, 获取到新好友的 id 和 name,
同时发送欢迎消息
1 | # plugins/AcceptFriend/main.py |
群聊新成员欢迎
通过使用正则表达式解析消息内容, 获取到新成员的 id 和
name, 并查询微信数据库, 获取到用户头像链接,
整合至欢迎消息中发送给新成员
1 | # plugins/GroupWelcome/main.py |
中药药方查询
在完成创新项目时, 我想到了通过微信来搭建中医问诊自动化的平台. 恰好本人在中医方面也略懂一些皮毛, 结合自己对于不同药方的病症的汇总与整理, 便通过决策树实现了这一功能.
多轮对话实现方式
1
2
3
4
5
6
7
8
9
10
11
12
13# plugins\TCM\main.py
self.users = {} # 正在问诊的用户
if msg.content.startswith('q '):
# 如果该用户已经在问诊中,则发送提示信息
if msg.sender in self.users:
bot.sendMsg("你已经处于一个问诊中了, 黑名单指数+1, 请注意", to, at)
# 将该用户加入黑名单,黑名单指数+1
await LegendBotDB.add_black(wxid=msg.sender, n=1)
return
# 更新问诊状态
if msg.content in self.users[msg.sender]:
self.users[msg.sender] = self.users[msg.sender][msg.content]决策树实现方式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
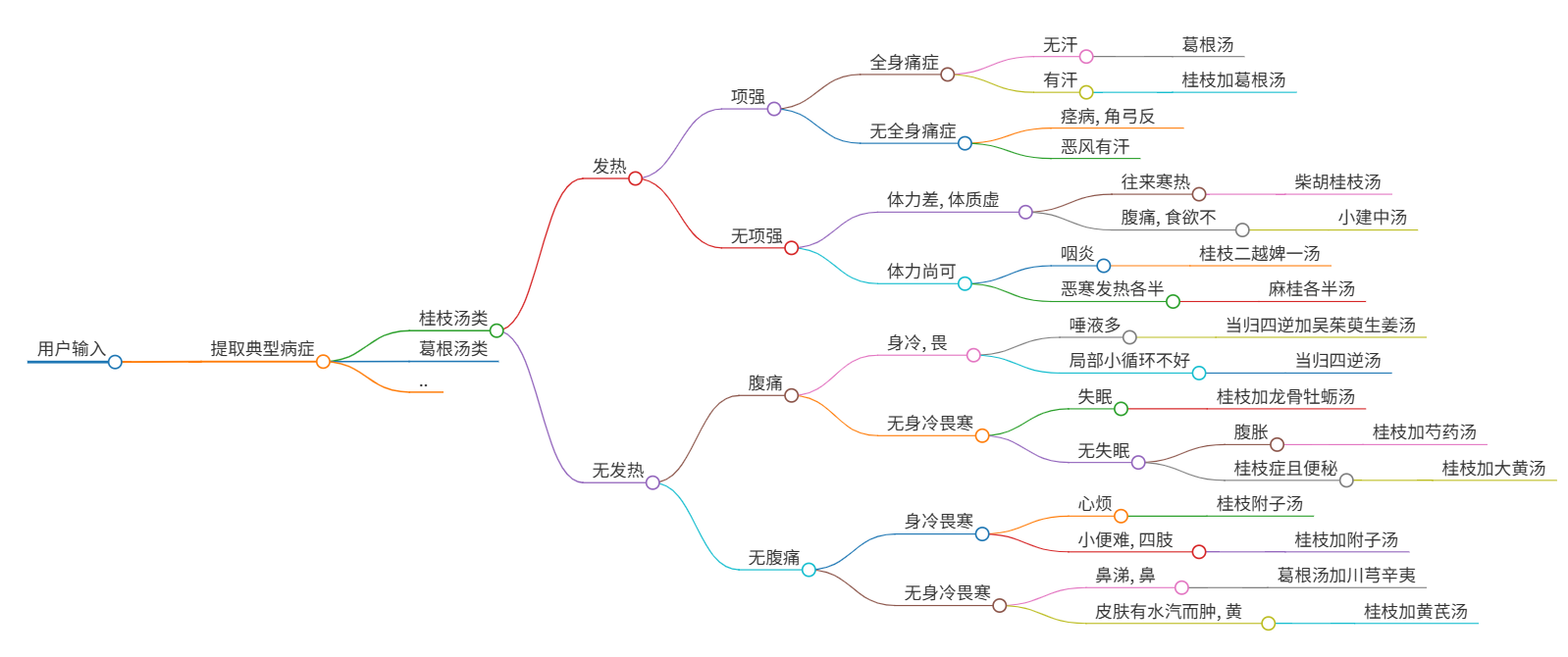
51<!-- 以桂枝汤系为例 -->
桂枝汤:
q: 发热吗?(有/没有)
有:
q: 头部后颈有牵扯不适的感觉吗?(有/没有)
有:
q: 全身酸痛吗?(酸痛/不酸痛)
酸痛:
q: 平时有汗吗?(有/没有)
有: 桂枝加葛根汤
没有: 葛根汤
不酸痛:
q: 痉(挛), 角弓反张, 即头和下肢后弯, 躯干向前; 或是怕风/自发性出汗吗?(痉症/恶风有汗)
痉症: 栝蒌桂枝汤
恶风有汗: 桂枝汤
没有:
q: 平时体力体质好吗?(好/不好)
好:
q: 咽炎, 咽部难受; 或是自觉怕冷, 哪怕加衣服靠近暖气也不见好, 且同时发热?(咽炎/恶寒发热)
咽炎: 桂枝二越婢一汤
恶寒发热: 麻桂各半汤
不好:
q: 有时自觉怕冷, 哪怕加衣服靠近暖气也不见好, 有时发热; 或是肚子疼, 食欲不振?(往来寒热/腹痛)
往来寒热: 柴胡桂枝汤
腹痛: 小建中汤
没有:
q: 肚子疼吗?(疼/不疼)
疼:
q: 怕冷但是可通过穿衣服等操作缓解吗?(是/不是)
是:
q: 唾液多; 或是身体局部气血不通, 胸闷/手脚冷/痉(挛), 角弓反张, 即头和下肢后弯, 躯干向前等?(唾液多/气血不通)
唾液多: 当归四逆加吴茱萸生姜汤
气血不通: 当归四逆汤
不是:
q: 失眠吗?(有/没有)
有: 桂枝加龙骨牡蛎汤
没有:
q: 肚子胀; 或是便秘?(肚子胀/便秘)
肚子胀: 桂枝加芍药汤
便秘: 桂枝加大黄汤
不疼:
q: 怕冷但是可通过穿衣服等操作缓解吗?(是/不是)
是:
q: 心烦; 或是小便困难, 四肢活动受限?(心烦/小便困难)
心烦: 桂枝附子汤
小便困难: 桂枝加附子汤
不是:
q: 有鼻涕, 较浓, 可能还会流到咽部; 或是皮肤表面有水肿, 有黄色的汗?(鼻涕/黄汗)
鼻涕: 葛根汤加川芎辛夷
黄汗: 桂枝加黄耆汤
首轮问询中相关性匹配实现方式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
def find_most_similar_question(tree, user_input):
# 遍历树形结构,返回所有问题及其路径
def traverse_tree(tree, path=[]):
# 定义一个空列表,用于存储问题及其路径
questions = []
# 遍历树形结构的每个节点
for key, value in tree.items():
# 如果节点的值是一个字典
if isinstance(value, dict):
# 如果字典中包含问题
if 'q' in value:
# 将问题及其路径添加到列表中
questions.append((value['q'], path + [key]))
# 递归调用traverse_tree函数,继续遍历子节点
questions.extend(traverse_tree(value, path + [key]))
# 返回问题及其路径的列表
return questions
questions = traverse_tree(tree)
question_texts = [q[0] for q in questions]
most_similar = difflib.get_close_matches(user_input, question_texts, n=3, cutoff=0.0)
paths = []
ques = []
if most_similar:
for question, path in questions:
if question in most_similar:
paths.append(path)
ques.append(question)
return paths, ques
return [], []
张维为表情包查询
在开发过程中, 好友 Daniel
基于bge-large-zh中文嵌入模型模型开源了一个张维为表情包匹配网站
VVQuest,
我将其处理成插件形式, 删除了不需要的部分(如前端),
并将其集成到项目中.
二次开发 首次运行前请自行下载
bge-large-zh模型, 并将其放置在plugins/VVQuest/data/models目录下. 首次运行时会自动生成缓存, 请耐心等待代码出处及详细开发文档请参见 VVQuest
敏感词检测
由于基于微信平台, 并对公众开放, 所以需要针对某些损害公共利益以及环境的行为进行检测, 其中就包含了敏感词检测, 在开发过程中, 我编写了敏感词检测程序并集成了敏感词库存放在docs/ban.txt
- 敏感词检测程序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124class DFA:
def __init__(self):
self.ban_words_set = set()
self.ban_words_list = []
self.ban_words_dict = {}
self.path = 'docs/ban.txt'
self.get_words()
# 获取敏感词列表
def get_words(self):
with open(self.path, 'r', encoding='utf-8-sig') as f:
for s in f:
if s.find('\\r'):
s = s.replace('\r', '')
s = s.replace('\n', '')
s = s.strip()
if len(s) == 0:
continue
if str(s) and s not in self.ban_words_set:
self.ban_words_set.add(s)
self.ban_words_list.append(str(s))
self.add_hash_dict(self.ban_words_list)
# 将敏感词列表转换为DFA字典序
def add_hash_dict(self, new_list):
for x in new_list:
self.add_new_word(x)
# 添加单个敏感词
def add_new_word(self, new_word):
new_word = str(new_word)
# print(new_word)
now_dict = self.ban_words_dict
i = 0
for x in new_word:
if x not in now_dict:
x = str(x)
new_dict = dict()
new_dict['is_end'] = False
now_dict[x] = new_dict
now_dict = new_dict
else:
now_dict = now_dict[x]
if i == len(new_word) - 1:
now_dict['is_end'] = True
i += 1
# 寻找第一次出现敏感词的位置
def find_illegal(self, _str):
now_dict = self.ban_words_dict
i = 0
start_word = -1
is_start = True # 判断是否是一个敏感词的开始
while i < len(_str):
if _str[i] not in now_dict:
if is_start is True:
i += 1
continue
i = start_word +1
start_word = -1
is_start = True
now_dict = self.ban_words_dict
else:
if is_start is True:
start_word = i
is_start = False
now_dict = now_dict[_str[i]]
if now_dict['is_end'] is True:
return start_word
else:
i += 1
return -1
# 查找是否存在敏感词
def exists(self, s):
pos = self.find_illegal(s)
if pos == -1:
return False
else:
return True
# 将指定位置的敏感词替换为*
def filter_words(self, filter_str, pos):
now_dict = self.ban_words_dict
end_str = int()
for i in range(pos, len(filter_str)):
if now_dict[filter_str[i]]['is_end'] is True:
end_str = i
break
now_dict = now_dict[filter_str[i]]
num = end_str - pos + 1
filter_str = filter_str[:pos] + '*'*num + filter_str[end_str + 1:]
return filter_str
def filter_all(self, s):
pos_list = list()
ss = self.draw_words(s, pos_list)
illegal_pos = self.find_illegal(ss)
while illegal_pos != -1:
ss = self.filter_words(ss, illegal_pos)
illegal_pos = self.find_illegal(ss)
i = 0
while i < len(ss):
if ss[i] == '*':
start = pos_list[i]
while i < len(ss) and ss[i] == '*':
i += 1
i -=1
end = pos_list[i]
num = end-start+1
s = s[:start] + '*'*num + s[end+1:]
i += 1
return s
def draw_words(_str, pos_list):
ss = str()
for i in range(len(_str)):
if '\u4e00' <= _str[i] <= '\u9fa5' or '\u3400' <= _str[i] <= '\u4db5' or '\u0030' <= _str[i] <= '\u0039' \
or '\u0061' <= _str[i] <= '\u007a' or '\u0041' <= _str[i] <= '\u005a':
ss += _str[i]
pos_list.append(i)
return ss
敏感词需要在所有插件处理前单独判断, 因此不作为插件出现
- 敏感词检测逻辑
1
2
3
4if dfa.exists(msg.content):
self.DB.add_black(msg.sender, 2)
self.bot.sendMsg('说话太刑了, 黑名单指数+2, 请注意', to, at)
return
社区贡献指南
🚩 提交代码时请使用标准化 Commit Message:
feat: 新功能fix: Bug修复docs: 文档更新style: 代码格式ref: 代码重构perf: 性能优化test: 测试相关chore: 构建/工具变更
提交贡献步骤
- Fork项目仓库:在GitHub上找到你想要贡献的项目,点击项目页面上的”Fork”按钮
- 克隆仓库到本地:使用git clone命令将你Fork的项目克隆到本地
- 创建新分支:在本地仓库中创建一个新分支进行你的工作,这是一个良好的实践。使用git checkout -b branch-name创建并切换到新分支
- 提交更改:使用git add和git commit命令提交你的更改
- 推送更改到GitHub:使用git push origin branch-name将更改推送回你的GitHub仓库
- 创建Pull Request:在GitHub上,你会看到一个”Compare & pull request”按钮。点击它,填写PR的标题和描述,然后提交
todo list
- 黑名单阈值, 达到阈值后直接不响应并踢出群聊
- 群管理制度, 结合群众力量管理社区氛围
- 实现引用消息相关的功能, 如下载引用的图片
- 表情包生成插件
项目已开源至 Github ,欢迎star和fork 若你觉得对你的开发有帮助, 或是对你的生活提供了方便, 欢迎来 爱发电 赞助
如果想一起开发或贡献插件等, 欢迎在相关标准制定后按照标准提交PR, 或 联系作者

