数学建模——快递站距离最小化

数学建模——快递站距离最小化
Kanwuqing1. 情景引入
在现代校园生活中, 快递服务已成为师生不可或缺的部分假设我们需要在校园内设立一个快递站, 服务于校内的学生
提出问题
- 驿站选点能否让大部分师生在日常生活中大概率经过至少一次
- 如何选点, 使得从校园内所有需求点出发, 抵达驿站的总取件路程最小
- 若要求每个需求点到达驿站的距离最远不超过
, 最少需要设置多少个驿站? - 考虑通行时间以及人流关于时间的分布, 如何使得师生等待时间尽可能少?
上述问题中, 考虑可行性, 选择问题2与问题4
2. 数学理想化加工
面对复杂的校园环境, 我们首先进行合理的简化与假设:
道路网络简化: 校园主干道构成一个连通无环的网络, 即任意两个路口之间只有唯一一条路径
站点位置限制: 快递站必须建立在路口(节点)上, 而非道路中间
路径行为: 学生文明有道德, 即沿着道路行走, 不能穿越建筑或草坪
需求分布: 每个宿舍区的学生人数可以归属于其最近的路口, 即每个路口设置一个需求权重, 这个数值可以通过调查宿舍区名单等轻易获得
一些其他现实细节
- 只考虑平面移动距离
- 只考虑从需求点前往驿站的时间, 不考虑后续返回的时间
- 将所有人步行速度视为相同
- 驿站只能建在指定位置, 不可任意选择 (可与需求点重合)
- 师生总是选择最优路线
3. 概念界定
3.1 距离的定义
一个简单的想法是直接使用两点间连线的距离来衡量, 即欧氏距离.但是校园道路环境复杂, 校园中存在建筑物、绿化带、围墙等障碍, 师生无法沿直线行走, 简单将距离视为欧氏距离与实际情况偏差较大, 需要考虑校园内道路情况 (如图所示, 蓝黄两条道路相差甚远). >曼哈顿距离也仅仅适用于区块类型的图, 在此情境中普适性不高

4. 模型建立
为了表现出这种道路的约束, 不妨将校园抽象成一张图:
- 顶点集
: 每个需求点抽象为一个节点, 每个节点具有权重, 代表该需求点的取件人数需求 - 边集
: 道路抽象为两个节点之间连接的边, 两个节点之间由边相连代表两个地点之间可互相到达 - 边权
: 边具有长度, 可直接记录为通行时间. - 点权
: 赋予一个非负权值 , 表示该路口所服务的学生人数
这样,
整个校园就被简化为由若干个节点和连接它们的边的图

然而, 图的结构较为复杂, 两个地点之间可能存在不止一条路径 (如上图中, 从节点1到节点3, 可以为1->2->3, 也可以为1->2->4->3), 形成一个环状结构.为了简便计算, 我们希望图中任意两点间有且仅有一条路径, 且可以证明这条路径是唯一的 (详见下文), 此时将图简化为树
即使校园结构中存在环, 我们只考虑师生选择最优路线情况下的总路程, 如果存在两条相等长度的路径, 我们可以保留任意一条。从而可将图化简为树, 即图的最小生成树(详见9.3.1
4.2 目标函数
设快递站建立在顶点
我们的目标是找到使
5. 建树引入
根据假设, 校园道路网络无环, 因此图
想象一棵真实的树:
- 从一片叶子到另一片叶子, 必须经过它们的”最近公共父节点”, 路径就是从第一个节点向上走到这个祖先, 再向下走到第二个节点. 因为树没有环, 所以不可能有两条不同的路径
- 不可能有两条不同的树枝路线连接两片叶子
- 如果存在两条路径, 就会形成”环”, 那就不是树了
例如, 在下面这棵树中: 1
2
3
4
5 A
/ \
B C
/ \ \
D E F
树的性质:
- 有
个顶点和 条边 - 任意两顶点间有且仅有一条简单路径
- 无环连通, 是最简单的连通图
现实生活中, 校园道路为了避免交通拥堵和迷路, 常常设计成树状结构, 这是一种从主干道不断分出支路的一种结构, 这种”分叉而不回头”的结构天然无环
这个性质很重要, 因为它意味着:
- 两点间的距离是明确定义的
- 计算距离变得简单直接
树的结构为我们使用重心这一工具奠定了基础
6. 初步思考最优化路径
直接枚举所有顶点计算
观察目标函数
7. 重心引入
7.1 树的重心的定义
为了理解重心, 我们先理解子树的概念:
子树: 对于树中的任意一个顶点
例子: 1
2
3
4
5 A
/|\
B C D
/| |
E F G
- 以
为根的子树包含: - 以
为根的子树就是整棵树 (因此 也被称为根节点) - 以
为根的子树只包含 自己
对于一棵带权树
形式化地, 记
例子: 1
2
3
4
5 A(10)
|
B(0)
/ | \
C(5) D(5) E(10)
- 删除
: 得到四个分支 , 最大权重 - 删除
: 得到一个大分支 , 权重 , 删除 同理 - 所以
是重心
性质: 一棵树至少有一个重心, 至多有两个重心若有两个重心, 则它们相邻
7.2 重心与总运输成本的关系
核心定理: 对于带权树
证明:
假设
设边
- 对于子树
中的所有顶点, 距离减少 , 成本减少 - 对于其余顶点 (权重和为
), 距离增加 , 成本增加
总成本变化量:
由于
这意味着
因此,
8. 数学模型与算法
8.1 数学模型总结
输入:
- 树
, - 边权
, - 点权
,
输出: 重心编号
算法步骤:
- 任选一个根节点 (如
), 进行深度优先搜索 (DFS), 计算每个顶点 的子树权重和 (包括 自身的权重), 最终计算总权重 - 对于每个顶点
, 考察删除 后各连通分支的权重: - 对于
的每个子节点 , 分支权重为 - 对于父节点方向, 分支权重为
取这些权重的最大值, 记为
- 对于
- 找出使
最小的顶点, 即为重心
一言以蔽之, 就是寻找所有节点中子节点和父节点权重最大值最小的节点
时间复杂度:
8.2 示例计算
考虑一棵简单的树: 1
2
3
4
5
6 A(10)
|
B(0)
/ \ \
/ \ \
C(5) D(5) E(10)
- 顶点B: 删除后, 分支权重分别为10、5、5、10, 最大为10 ≤15?
- 实际上分支有四个: A(10)、C(5)、D(5)、E(10), 最大为10 ≤15, 且没有其他顶点满足更小的最大分支权重, 因此B是重心
验证计算
比较
8.3 更复杂的示例
考虑一个更复杂, 更贴合实际的例子: 1
2
3
4
5
6
7
8
9 A(5)
/ \
2/ \3
/ \
B(3) C(2)
/ \ \
1/ \4 \2
/ \ \
D(1) E(4) F(6)
总权重
计算子树权重(以A为根, 后序遍历):
检查每个节点是否满足重心条件(即删除该节点后, 每个连通分支的权重和 ≤ 10.5):
- 节点
: 删除 后, 得到两个连通分支: 权重和为8, 权重和为8, 两个都 ≤10.5, 所以A可能是重心 - 节点
: 删除 后, 得到三个连通分支: 权重和为 , 权重1, 权重4其中 , 所以B不是重心 - 类似的, 其他节点也可以确定不是重心
因此,
验证总运输成本:
现在计算每个节点作为快递站时的总成本
计算S(A):
到 : 到 : 距离2, 权重3, 贡献 到 : 距离3, 权重2, 贡献 到 : 距离 , 权重1, 贡献 到 : 距离 , 权重4, 贡献 到 : 距离 , 权重6, 贡献
类似地,
8.4 我们的方案——据海中学真实案例
在Butterfly所在的据海中学,
急需这样一个驿站供学生老师收取外卖与快递,
经过颂舟寒同学的考察, 绘制出了这样一张图 (地图见上文
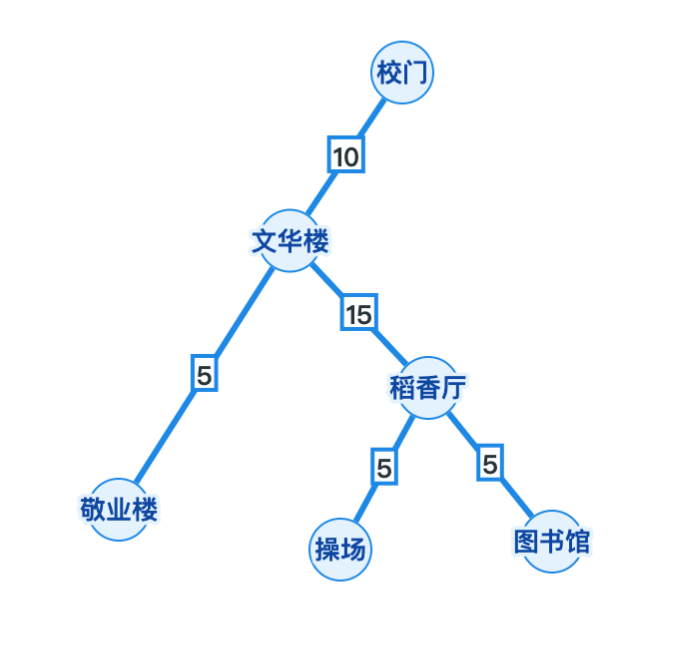
通过采取上文相同的做法: 以校门为树的根节点, 进行搜索, 计算各节点到校门的距离, 其中图书馆与操场最远, 均为30
对比每个节点的子节点和父节点权重最大值,
Danial同学发现这棵树有两个重心,
分别是校门和稻香厅 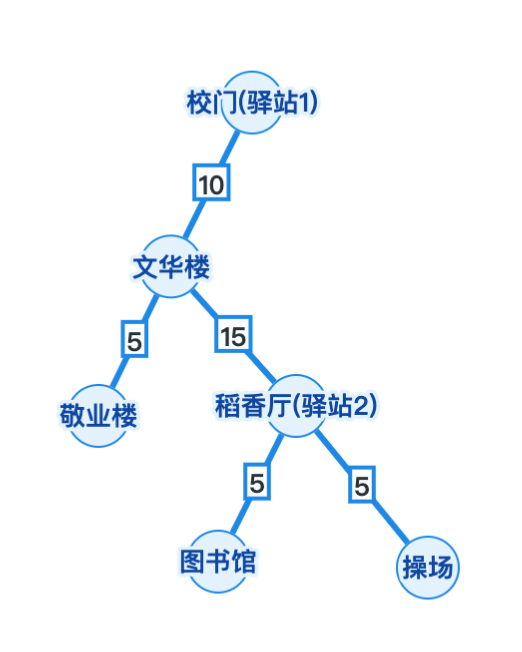
由此可以得出: 若据海中学希望建立驿站, 有两个选择, 从而方便全校师生
9. 反思与思考
9.1 模型的优点
- 数学优美: 将实际问题转化为树的重心问题, 有严格的数学证明
- 计算高效:
算法可快速求解大规模问题 - 直观易懂: 重心平衡各方向需求, 符合直觉
9.2 模型的局限性 (主要评估与现实不符之处)
- 道路网络未必是树: 实际校园可能存在环形道路, 形成图中环
- 需求点未必在节点: 宿舍可能位于道路中间, 需插值处理
- 单点服务限制: 大型校园可能需要多个快递站
- 忽略其他因素: 如地形坡度、道路拥堵、安全因素等, 更重要的是宿舍楼很有可能是建在边上的, 这意味着要对边权进行整合
9.3 优化方向
- 处理一般图: 若道路有环, 可将原图转化为最小生成树,
或直接使用图论中的“图中心” (最小化最大距离)或“图中位点”
(最小化总距离)概念计算图中位点需所有点对最短路径
(最小生成树可使用Floyd算法, 时间复杂度
) - 多设施选址: 若需建立
个快递站, 问题变为 -中心问题 或 -中位问题, 可使用聚类算法 (如K-means算法)先将顶点分区, 每区求一个重心 (人工智能领域算法基础) - 从信息学算法角度考虑, 之前提到的深度优先搜索可以通过递推链, 构造动态转移方程等方式转化为动态规划算法(DP)从而降低时间复杂度, 由于篇幅原因此处不作过多讨论
- 动态权重: 学生人数可能随时间 (学期、节假日)变化, 可引入动态权重并研究鲁棒解
(附)9.4 对于整合边权进入模型的可行性分析
在之前的案例中, 只是简单地将边权作为长度权重进行了简单的数乘, 而在现实中, 宿舍楼通常沿着道路分布, 而不是全部挤在路口, 对此需要重新定义边权和总需求
- 边权包含两部分:
- 长度权
: 道路的实际长度 - 需求权
或需求密度 : 表示沿这条道路分布的学生需求
- 长度权
- 总需求: 总学生数 =
混合模型目标函数
在树中, 从 1
2
3
4
5
6v
|
| dist(v,a)
|
a•---------------•b
← 0 < x < l(e) →
- 经过节点
: 路径长度 = - 经过节点
: 路径长度 =
取最小值:
然而在实际应用中, 通常不知道每个宿舍楼的确切位置, 但知道:
- 这条路上总共有多少学生
- 这些学生大致均匀分布在路上 (如宿舍楼中的学生)
所以, 我们假设:
现在我们要计算从
这个积分有闭式解, 也就是带入数值就能算出来, 不用牛顿迭代, 取决于
到两端点的距离. 具体积分过程本文不作具体讨论
则对于模型
混合模型的最优性思考
对于混合模型, 没有这样简洁的“重心定理”, 因为需求分布在边上, 删除一个节点不能完全分开边上的需求, 因此可以:
- 虚拟节点: 将每条边上的需求集中到中点或按比例分配到两端, 转化为一个近似的纯点权树, 然后应用重心定理
- 直接优化: 计算每个节点的
值, 取最小值通过预处理, 可在 内求解
算法思路(假设均匀分布):
- 预处理所有节点对之间的距离(
) - 对于每条边
, 预先计算其平均距离函数 关于 的表达式 - 对每个候选节点
, 计算: - 取使
最小的节点
应用比较
考虑之前提到的案例: 1
2
3
4
5
6
7
8
9 A(5)
/ \
2/ \3
/ \
B(3) C(2)
/ \ \
1/ \4 \2
/ \ \
D(1) E(4) F(6)
总权重
在原案例基础上, 假设:
- 节点权重不变:
- 新增边权重(表示沿路分布的学生):
边: 2人 边: 3人 边: 5人
- 边长度权不变
计算混合模型下的最优选址:
步骤1: 计算总需求 节点总需求
步骤2: 为简化, 采用虚拟节点法 (类比杠杆)
- 在
中点 : 权重2, 距离 为1, 距离 为1 - 在
中点 : 权重3, 距离 为2, 距离 为2 - 在
中点 : 权重5, 距离 为1, 距离 为1
得到扩展树: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21 A(5)
\
1 \
\
M1(2)
/
1 /
/
B(3)....B(3)
/ \ \
/ \ \
1/ \2 \
D(1) M2(3) C(2)
/ \
2/ 1 \
/ \
E(4) M3(5)
/
1 /
/
F(6)
步骤3: 在扩展树上寻找重心 扩展树总权重 = 31, 一半 = 15.5 通过计算(过程略)可找到重心位置 (步骤与纯点权模型相同)
步骤4: 对比两种模型的结果 假设我们计算得到:
- 纯点权模型最优: 节点A,
, 服务21人, 人均路程 = 69/21 ≈ 3.29 - 混合模型最优: 可能是节点B或其附近, 设
, 服务31人, 人均路程 = 85/31 ≈ 2.74
发现: 混合模型人均路程更低, 选址可能不同,
并且通过不断细化二分, 最终可以逼近一个确切的图上的点

